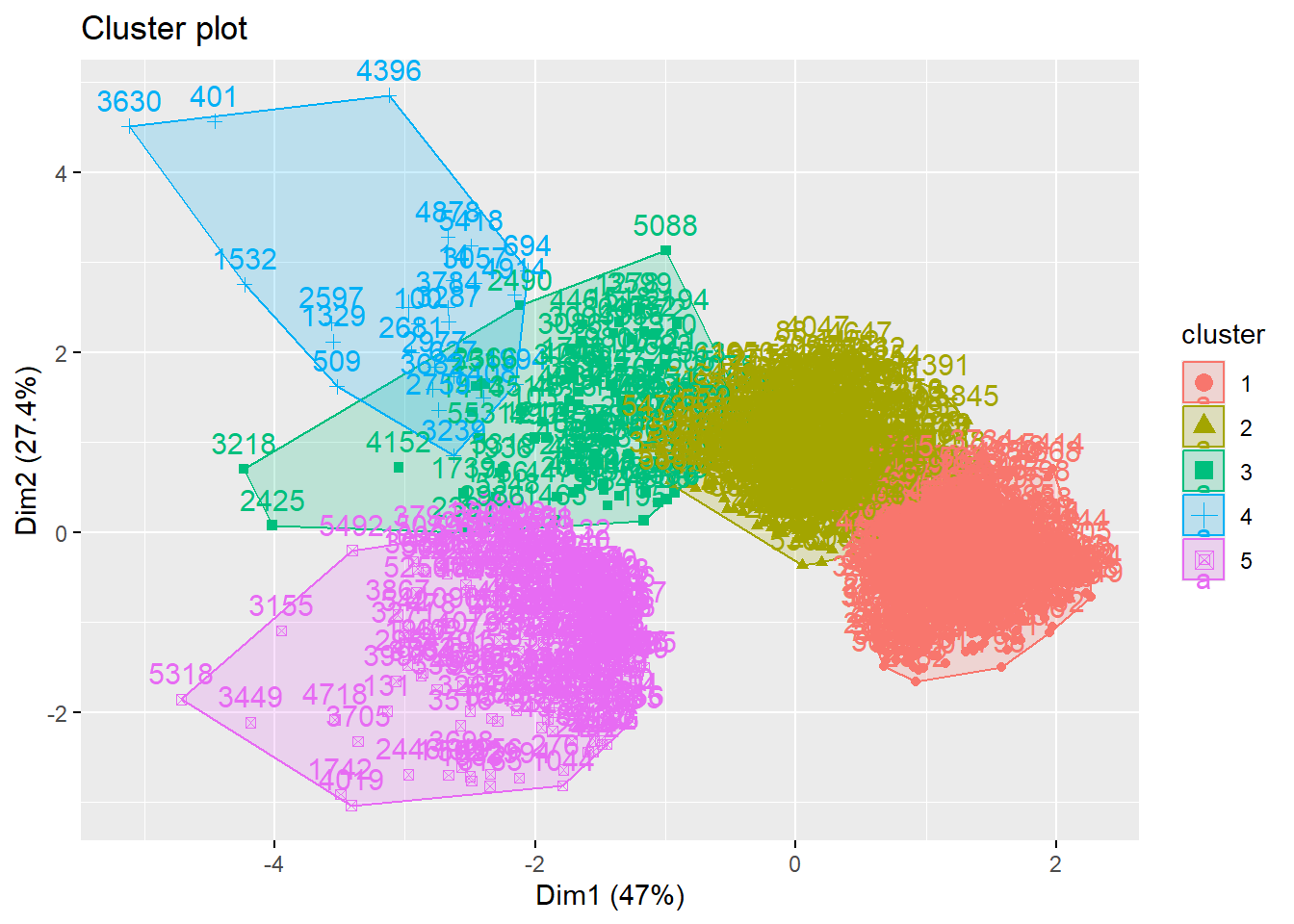
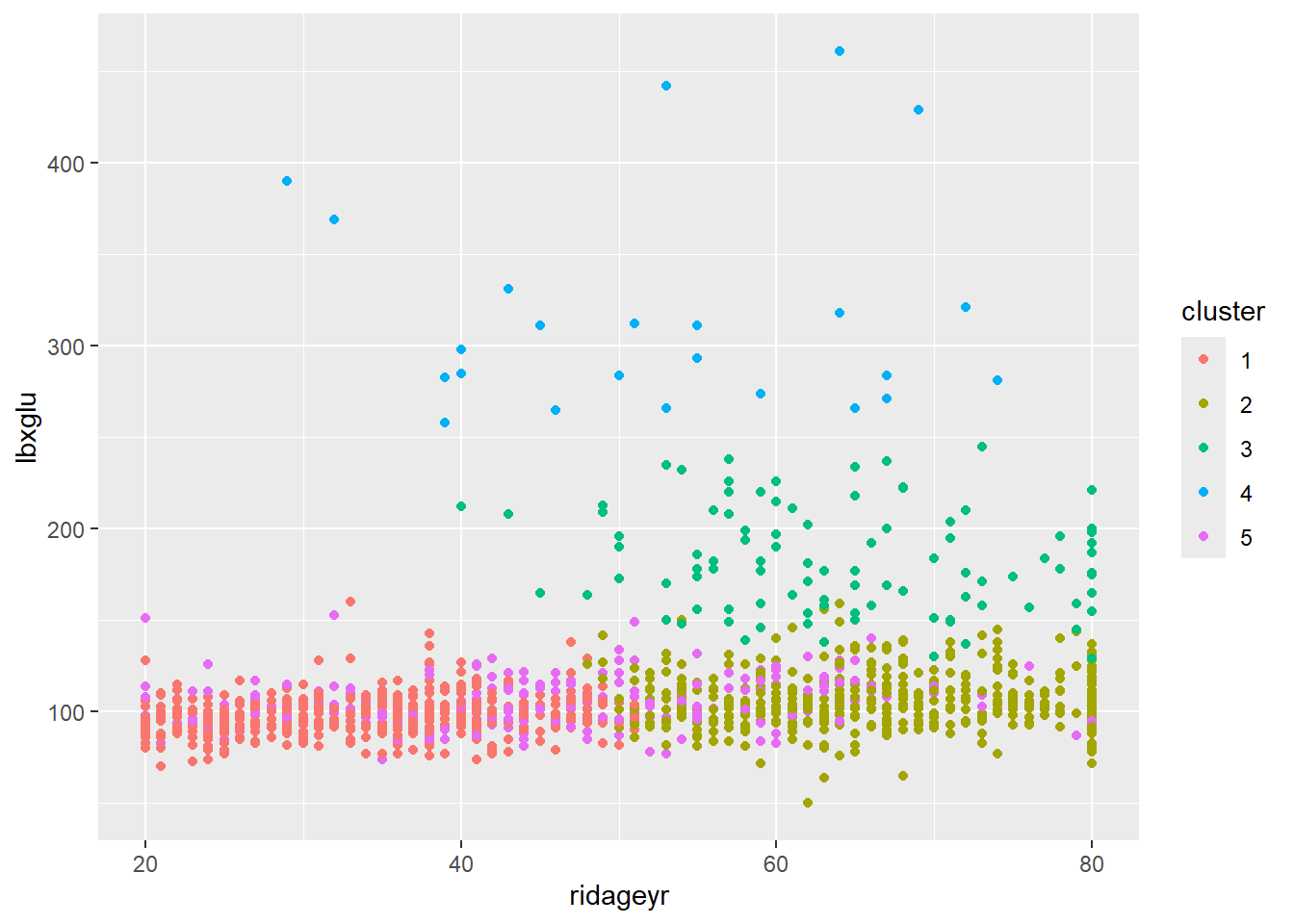
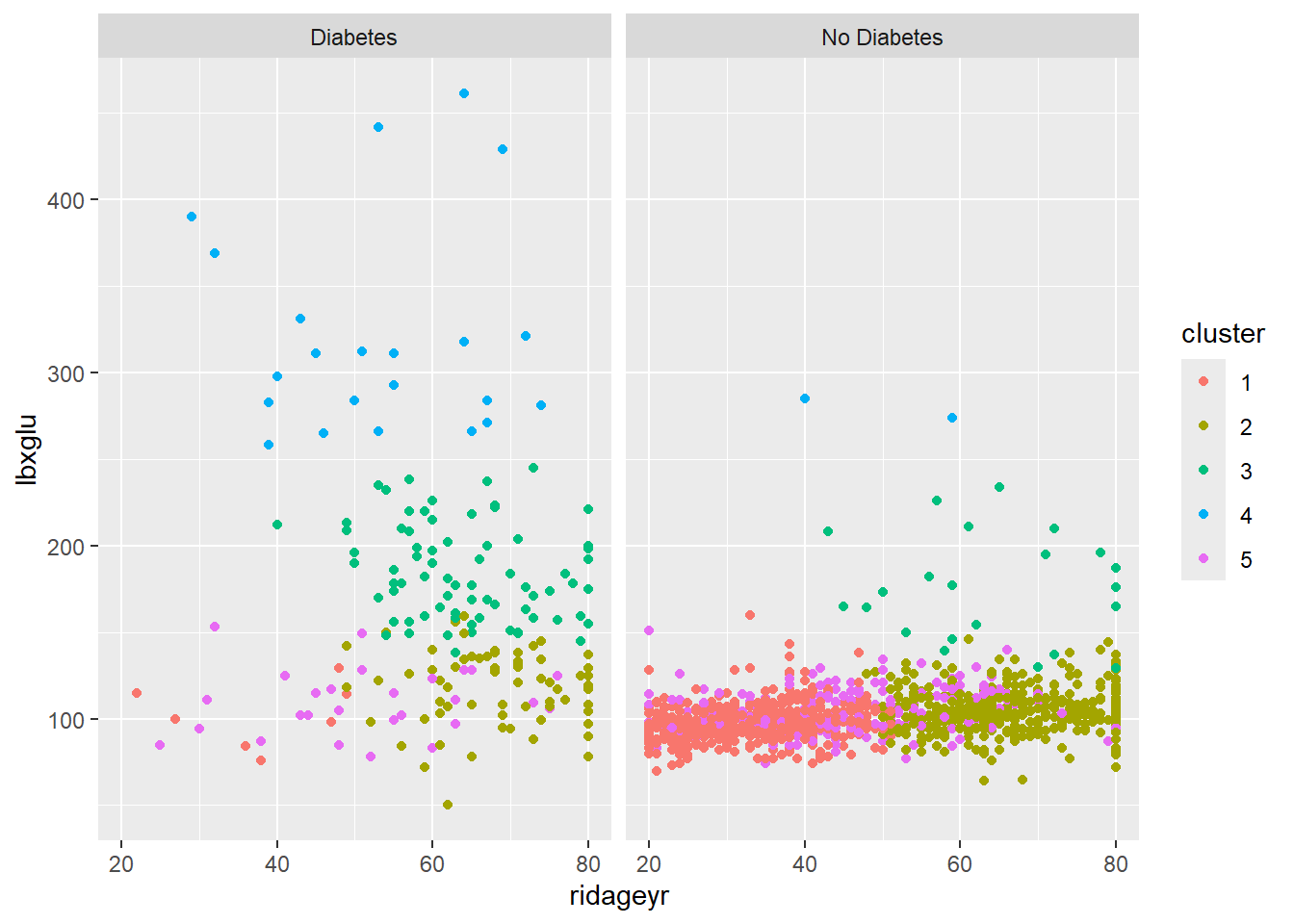
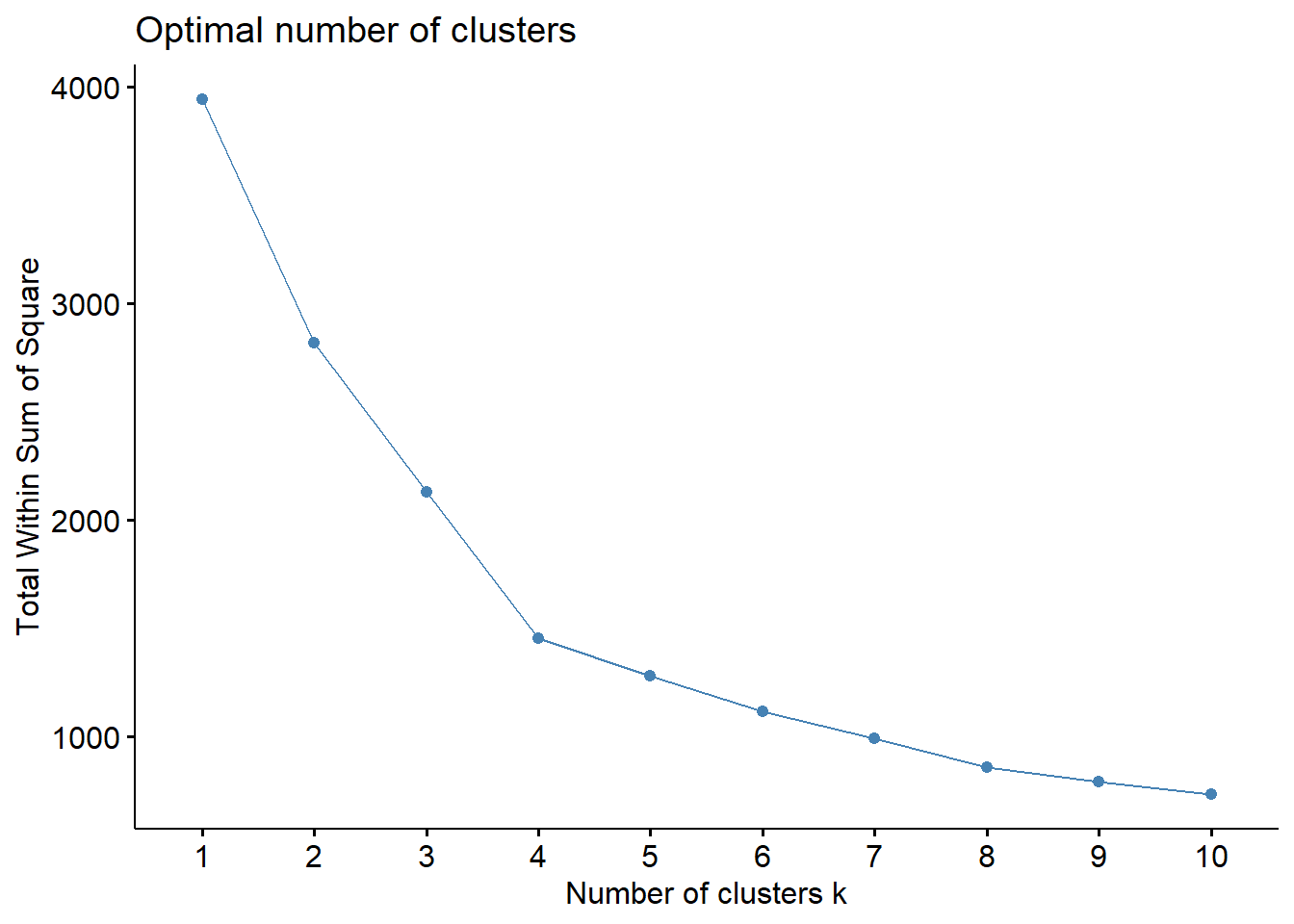Welcome to factoextra!
Want to learn more? See two factoextra-related books at https://www.datanovia.com/en/product/practical-guide-to-principal-component-methods-in-r/
Warning: Using an external vector in selections was deprecated in tidyselect 1.1.0.
ℹ Please use `all_of()` or `any_of()` instead.
# Was:
data %>% select(numeric_features)
# Now:
data %>% select(all_of(numeric_features))
See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.
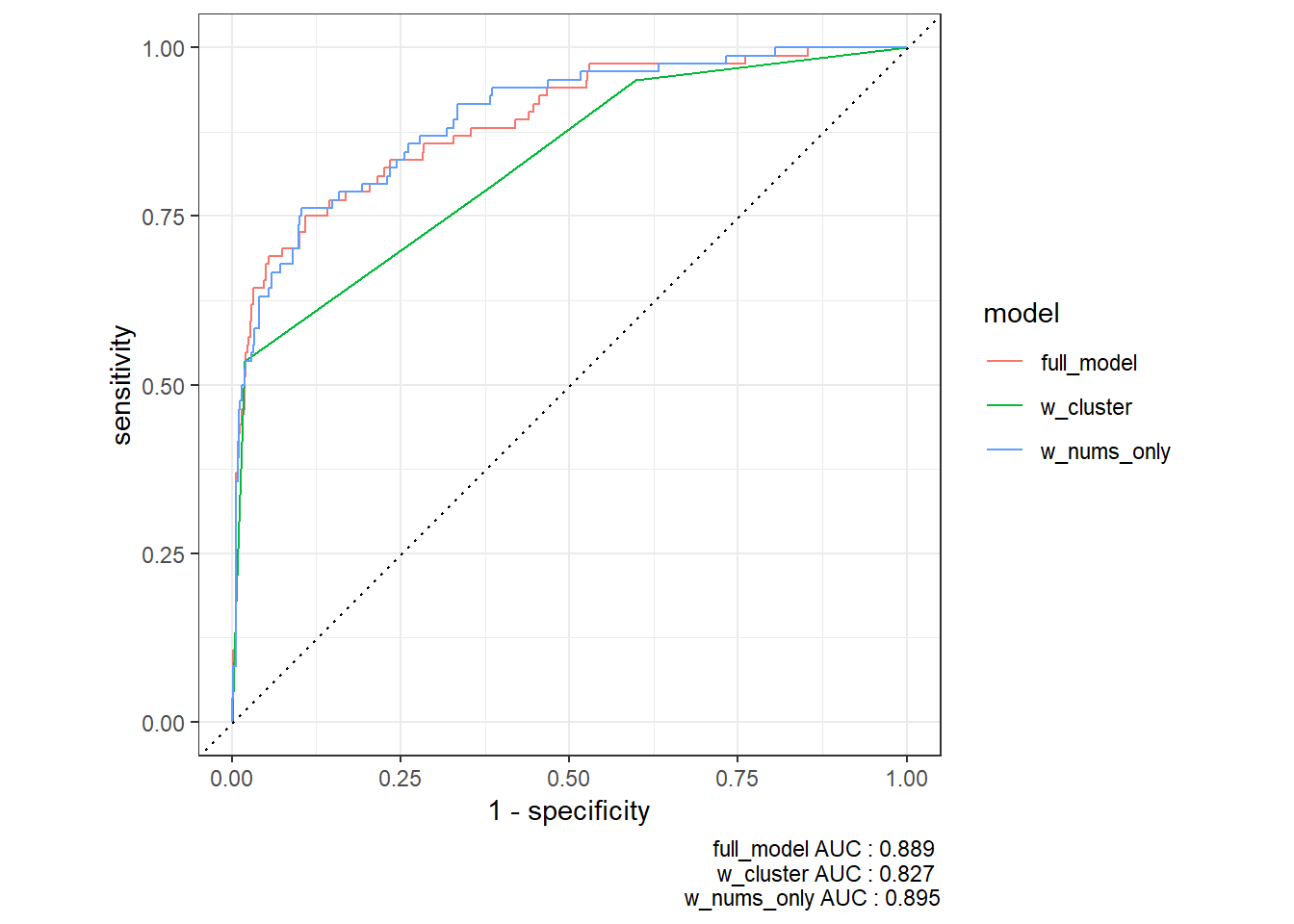
29.3 Train Clustering Model
# Set seed for reproducible resultsset.seed(1984)pP.TRAIN<-preProcess(TRAIN, c('center','scale'))# Run k-means algorithm# Nstart = # random starting positions; I chose 523km<-kmeans(predict(pP.TRAIN, TRAIN)%>%select(numeric_features), centers =5, nstart =523)glimpse(km)
List of 9
$ cluster : Named int [1:1314] 1 1 4 2 4 3 3 2 4 4 ...
..- attr(*, "names")= chr [1:1314] "2" "3" "11" "15" ...
$ centers : num [1:5, 1:3] 0.894 0.254 0.833 -0.893 -0.735 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:5] "1" "2" "3" "4" ...
.. ..$ : chr [1:3] "ridageyr" "bmxbmi" "lbxglu"
$ totss : num 3939
$ withinss : num [1:5] 317 172 273 264 208
$ tot.withinss: num 1234
$ betweenss : num 2705
$ size : int [1:5] 437 44 179 444 210
$ iter : int 4
$ ifault : int 0
- attr(*, "class")= chr "kmeans"
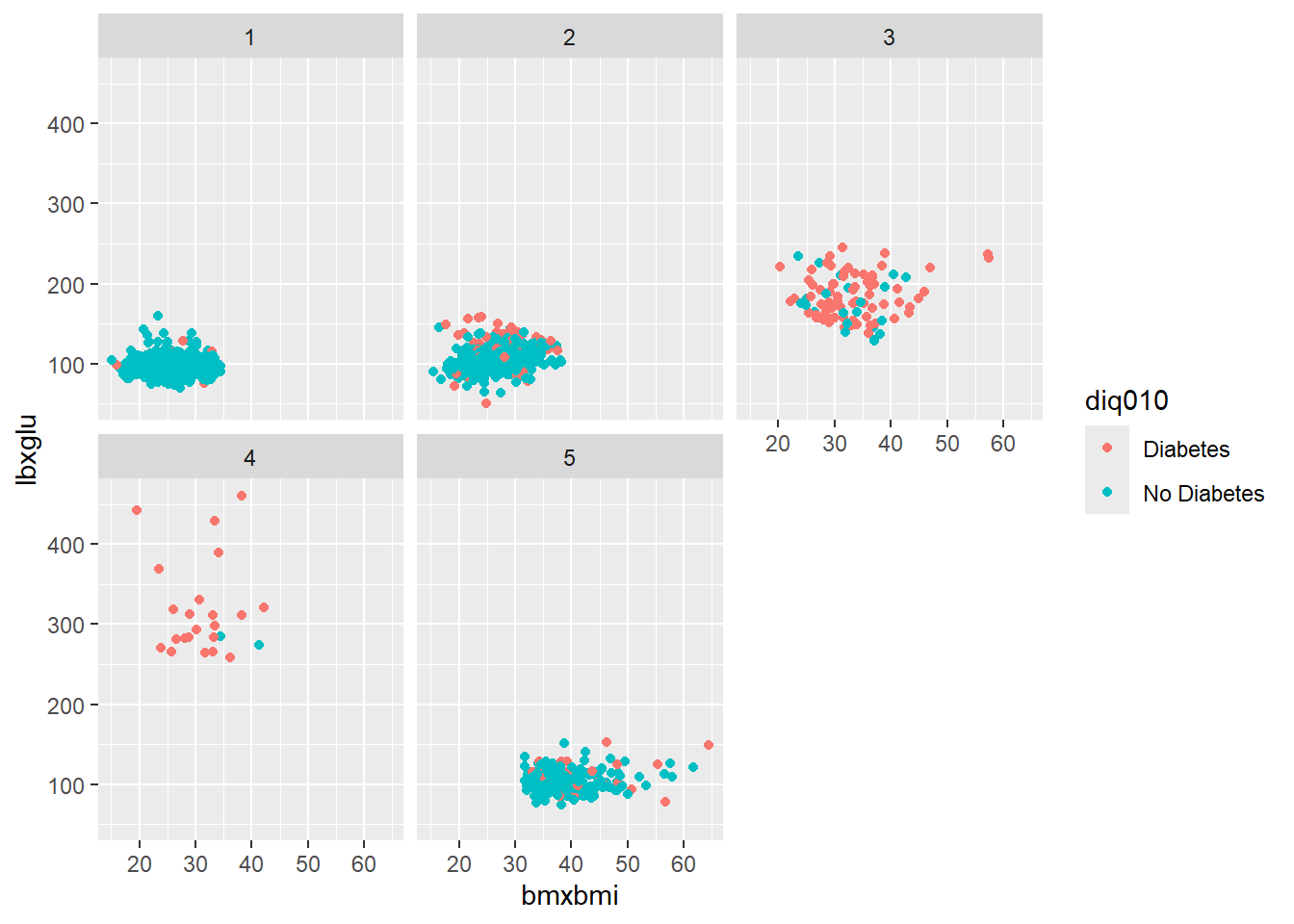
seqn riagendr ridageyr ridreth1 dmdeduc2
2 83733 Male 53 Non-Hispanic White High school graduate/GED
3 83734 Male 78 Non-Hispanic White High school graduate/GED
11 83750 Male 45 Other Grades 9-11th
15 83757 Female 57 Other Hispanic Less than 9th grade
17 83761 Female 24 Other College grad or above
29 83787 Female 68 MexicanAmerican Less than 9th grade
dmdmartl indhhin2 bmxbmi diq010 lbxglu cluster
2 Divorced $15,000-$19,999 30.8 No Diabetes 101 1
3 Married $20,000-$24,999 28.8 Diabetes 84 1
11 Never married $65,000-$74,999 24.1 No Diabetes 84 4
15 Separated $20,000-$24,999 35.4 Diabetes 398 2
17 Never married $0-$4,999 25.3 No Diabetes 95 4
29 Divorced $15,000-$19,999 33.5 No Diabetes 111 3
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999
Warning in preProcess.default(thresh = 0.95, k = 5, freqCut = 19, uniqueCut =
10, : These variables have zero variances: indhhin2$35,000-$44,999,
indhhin2$55,000-$64,999