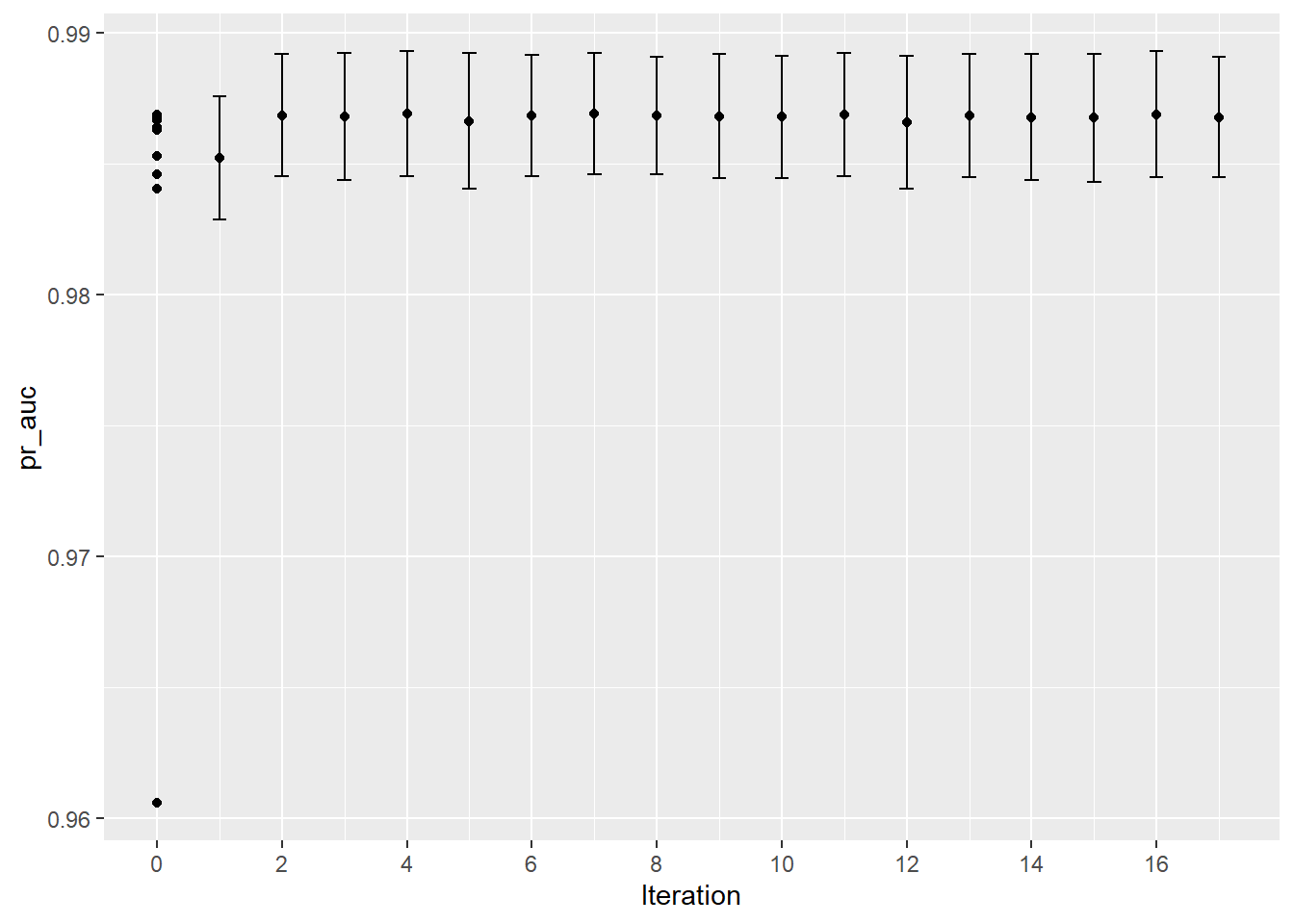
tic ( ) glmnet_tune <- glmnet_wflow %>% tune_bayes (
resamples = diab_folds ,
metrics = metric_set ( yardstick :: pr_auc ) ,
initial = glmnet_initial ,
param_info = glmnet_param ,
iter = 25 ,
control = control_bayes ( verbose = TRUE )
)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
i Fold01: preprocessor 1/1
i Fold01: preprocessor 1/1 (prediction data)
i Fold01: preprocessor 1/1, model 1/1
i Fold01: preprocessor 1/1, model 1/1 (predictions)
i Fold02: preprocessor 1/1
i Fold02: preprocessor 1/1 (prediction data)
i Fold02: preprocessor 1/1, model 1/1
i Fold02: preprocessor 1/1, model 1/1 (predictions)
i Fold03: preprocessor 1/1
i Fold03: preprocessor 1/1 (prediction data)
i Fold03: preprocessor 1/1, model 1/1
i Fold03: preprocessor 1/1, model 1/1 (predictions)
i Fold04: preprocessor 1/1
i Fold04: preprocessor 1/1 (prediction data)
i Fold04: preprocessor 1/1, model 1/1
i Fold04: preprocessor 1/1, model 1/1 (predictions)
i Fold05: preprocessor 1/1
i Fold05: preprocessor 1/1 (prediction data)
i Fold05: preprocessor 1/1, model 1/1
i Fold05: preprocessor 1/1, model 1/1 (predictions)
i Fold06: preprocessor 1/1
i Fold06: preprocessor 1/1 (prediction data)
i Fold06: preprocessor 1/1, model 1/1
i Fold06: preprocessor 1/1, model 1/1 (predictions)
i Fold07: preprocessor 1/1
i Fold07: preprocessor 1/1 (prediction data)
i Fold07: preprocessor 1/1, model 1/1
i Fold07: preprocessor 1/1, model 1/1 (predictions)
i Fold08: preprocessor 1/1
i Fold08: preprocessor 1/1 (prediction data)
i Fold08: preprocessor 1/1, model 1/1
i Fold08: preprocessor 1/1, model 1/1 (predictions)
i Fold09: preprocessor 1/1
i Fold09: preprocessor 1/1 (prediction data)
i Fold09: preprocessor 1/1, model 1/1
i Fold09: preprocessor 1/1, model 1/1 (predictions)
i Fold10: preprocessor 1/1
i Fold10: preprocessor 1/1 (prediction data)
i Fold10: preprocessor 1/1, model 1/1
i Fold10: preprocessor 1/1, model 1/1 (predictions)
! No improvement for 10 iterations; returning current results.
toc ( log = TRUE , quiet = FALSE )